独立な指数分布に従う2変数の和の確率
指数分布の和はガンマ分布に従います。
X1,X2は互いに独立でパラメータλを持つ指数分布に従います。
U=X1+X2とします
数式を使ってUの確率密度関数を求めます。
import sympy as sp
# 変数の定義
x, u, lambda_value = sp.symbols('x u lambda', positive=True, real=True)
# 指数分布の確率密度関数 (PDF) f(x)
f_x = lambda_value * sp.exp(-lambda_value * x)
# 畳み込み積分を計算して、g(u) = f(x) * f(u - x) の形式にする
g_u = sp.integrate(f_x * lambda_value * sp.exp(-lambda_value * (u - x)), (x, 0, u))
# 簡略化
g_u_simplified = sp.simplify(g_u)
# 結果の表示
display(g_u_simplified)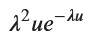
求まりました。
X1 (X2)と、Uの確率密度関数を重ねて描画してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2 の範囲
# X1, X2 の指数分布の確率密度関数 (PDF) - 同じなので1つにまとめる
pdf_X1_X2 = lambda_value * np.exp(-lambda_value * x_range)
# U = X1 + X2 は形状パラメータk=2、スケールパラメータθ=1/λのガンマ分布
u_range = np.linspace(0, 10, 1000)
pdf_U = gamma.pdf(u_range, a=2, scale=1/lambda_value)
# グラフのプロット
plt.figure(figsize=(8, 6))
# X1 (X2) の指数分布の描画
plt.plot(x_range, pdf_X1_X2, label='X1 (X2) (指数分布)', color='blue', linestyle='--')
# U のガンマ分布の描画
plt.plot(u_range, pdf_U, label='U = X1 + X2 (ガンマ分布)', color='red')
# グラフの装飾
plt.title('X1 (X2) と U の確率密度関数の比較')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.show()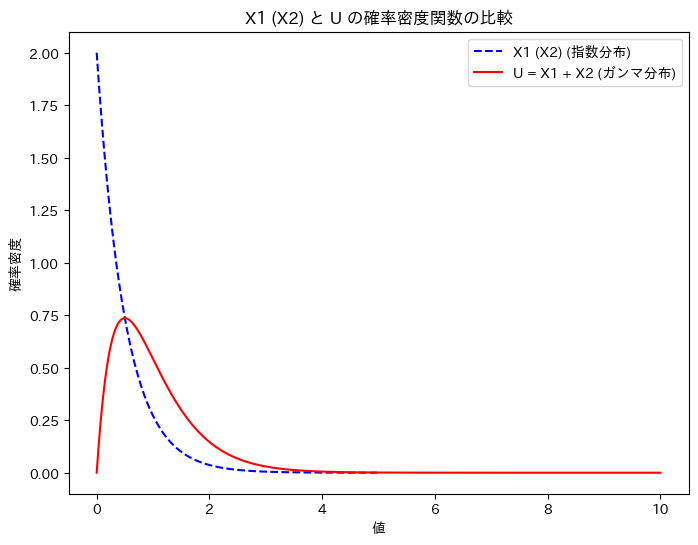
グラフの形状から、U = X1 + X2の関係は想像しづらいですね。
ガンマ分布の形状パラメータを1~2に変化させて、X1 (X2)からUへの変化を確認します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2, U の範囲を0~5に設定
# ガンマ分布の形状パラメータを1から2まで0.1ずつ変化させる
shape_params = np.arange(1, 2.1, 0.1) # 1から2までの形状パラメータを0.1ステップで変化
# グラフのプロット
plt.figure(figsize=(8, 6))
# 形状パラメータが1から2に変化するガンマ分布の描画
for k in shape_params:
gamma_pdf = gamma.pdf(x_range, a=k, scale=1/lambda_value)
plt.plot(x_range, gamma_pdf, label=f'形状パラメータ k={k:.1f}')
# X1 (X2) の指数分布の描画 - 同じなので1つにまとめる
pdf_X1_X2 = lambda_value * np.exp(-lambda_value * x_range)
plt.plot(x_range, pdf_X1_X2, label='X1 (X2) (指数分布)', color='blue', linestyle='--')
# グラフの装飾
plt.title('指数分布からガンマ分布への変化 (形状パラメータの0.1ステップ変化)')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.show()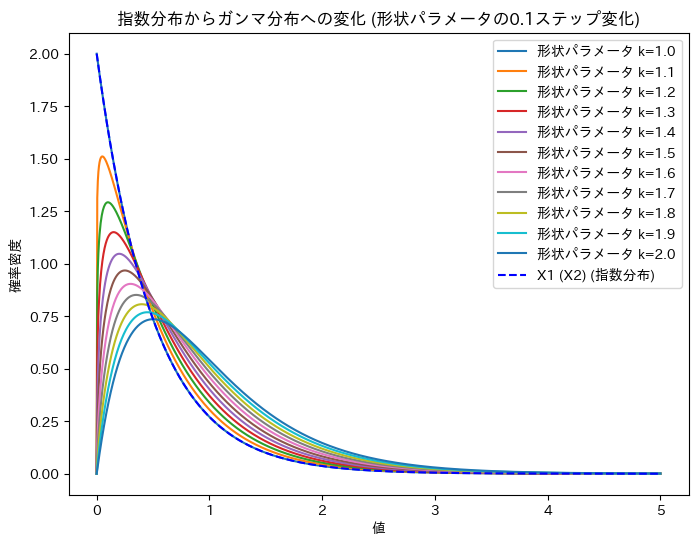
X1 (X2)からUへの変化が可視化できました。
次に、X1 (X2)と、Uの累積分布関数を重ねて描画してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import expon, gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2 の範囲
# X1, X2 の指数分布の累積分布関数 (CDF) - 同じなので1つにまとめる
cdf_X1_X2 = expon.cdf(x_range, scale=1/lambda_value)
# U = X1 + X2 は形状パラメータk=2、スケールパラメータθ=1/λのガンマ分布
u_range = np.linspace(0, 10, 1000)
cdf_U = gamma.cdf(u_range, a=2, scale=1/lambda_value)
# グラフのプロット
plt.figure(figsize=(8, 6))
# X1 (X2) の指数分布のCDFの描画
plt.plot(x_range, cdf_X1_X2, label='X1 (X2) (指数分布 CDF)', color='blue', linestyle='--')
# U のガンマ分布のCDFの描画
plt.plot(u_range, cdf_U, label='U = X1 + X2 (ガンマ分布 CDF)', color='red')
# グラフの装飾
plt.title('X1 (X2) と U の累積分布関数 (CDF) の比較')
plt.xlabel('値')
plt.ylabel('累積確率')
plt.legend()
# グラフの表示
plt.show()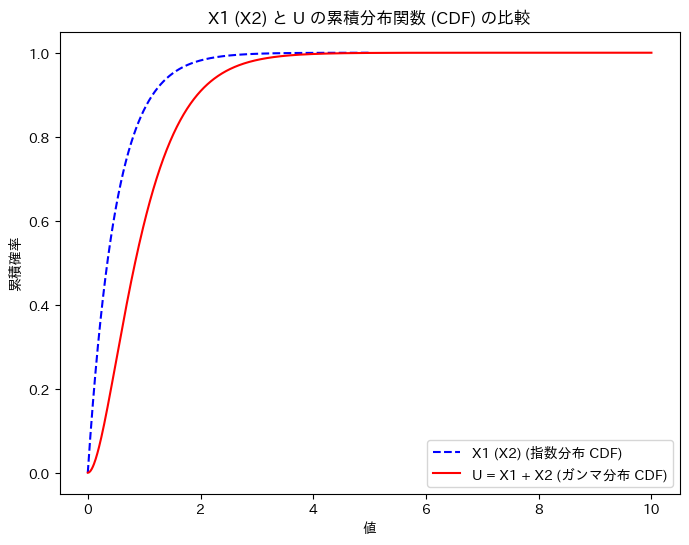
グラフの形状から、U = X1 + X2の関係を想像しやすくなりました。
確率母関数の不等式
不等式 を可視化して確認します。ここでは二項分布で試してみましょう。
を可視化して確認します。ここでは二項分布で試してみましょう。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
n = 10 # 二項分布の試行回数
p = 0.5 # 二項分布の成功確率
t_values = [0.001, 0.2, 0.4, 0.6, 0.8, 1] # t の値のリスト
sample_size = 10000 # サンプル数
r_values = np.arange(0, n+1, 1) # r の範囲を設定
# 確率母関数 G_X(t) の定義
def G_X(t, n, p):
return (p * t + (1 - p))**n
# 1. 二項分布から乱数を生成
samples = np.random.binomial(n, p, sample_size)
# 2. r に対する P(X <= r) の推定(左辺)
P_X_leq_r_values = [np.sum(samples <= r) / sample_size for r in r_values]
# サブプロットの作成
fig, axes = plt.subplots(2, 3, figsize=(15, 8)) # 2行3列のサブプロットを作成
# 3. 各 t に対するグラフを描画
for i, t in enumerate(t_values):
row = i // 3 # 行番号
col = i % 3 # 列番号
# 右辺 t^{-r} G_X(t) の計算
G_X_value = G_X(t, n, p) # 確率母関数の t 固定
right_hand_side_values = [G_X_value if t == 1 else t**(-r) * G_X_value for r in r_values] # t = 1 の場合はべき乗を回避
# グラフの描画
ax = axes[row, col]
ax.plot(r_values, P_X_leq_r_values, label="P(X <= r) (左辺)", color="blue", linestyle="--")
ax.plot(r_values, right_hand_side_values, label="t^(-r) G_X(t) (右辺)", color="red")
ax.set_title(f"t = {t}")
ax.set_xlabel("r")
ax.set_ylabel("値 (対数スケール)")
ax.set_yscale('log') # 縦軸を対数スケールに設定
ax.legend()
ax.grid(True, which="both", ls="--")
# サブプロット間のレイアウト調整
plt.tight_layout()
plt.show()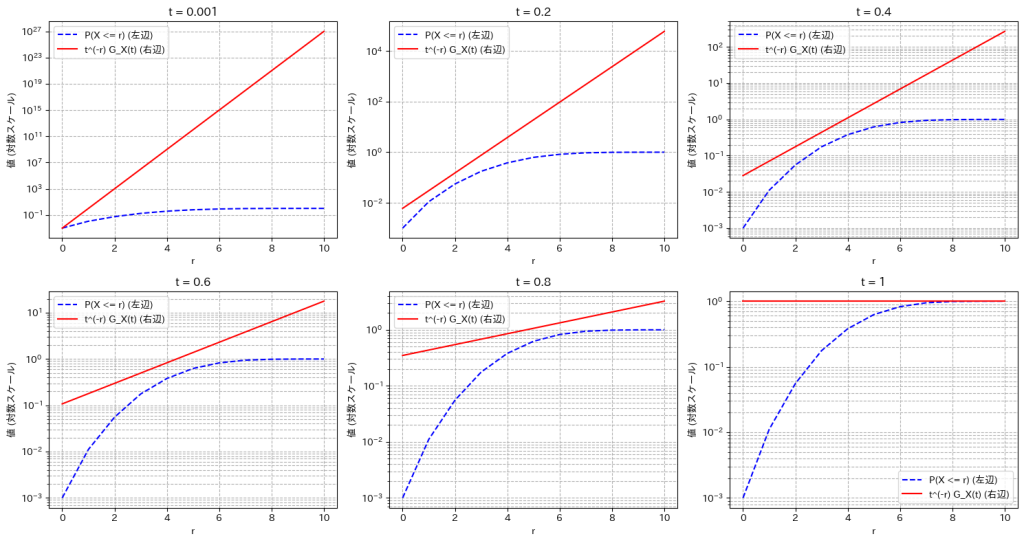
不等式が成り立っていることが確認できます。
次に、Xが二項分布B(n,p)に従うとき、aを実数、0<a<pに対し、不等式 が成り立つのか可視化しましょう。
が成り立つのか可視化しましょう。
import numpy as np
from scipy.stats import binom
import matplotlib.pyplot as plt
# パラメータ設定
n_values = [10, 30, 50] # 試行回数 n のリスト
p_values = [0.3, 0.5, 0.7] # 成功確率 p のリスト
a_values = np.linspace(0.01, 0.99, 50) # a の範囲
# サブプロットの作成
fig, axes = plt.subplots(3, 3, figsize=(15, 15)) # 3x3のグリッドでグラフを描画
# グラフの描画ループ
for i, n in enumerate(n_values):
for j, p in enumerate(p_values):
# 左辺と右辺の値を格納するリスト
left_side_values = []
right_side_values = []
for a in a_values:
# 左辺:P(X <= an) の計算
k = int(np.floor(a * n))
left_side = binom.cdf(k, n, p)
left_side_values.append(left_side)
# 右辺の計算
right_side = (p / a) ** (a * n) * ((1 - p) / (1 - a)) ** ((1 - a) * n)
right_side_values.append(right_side)
# グラフの描画(対数スケール)
ax = axes[i, j]
ax.plot(a_values, left_side_values, label='左辺 $P(X \leq an)$', color='blue')
ax.plot(a_values, right_side_values, label='右辺', color='red', linestyle='--')
# 0 < a < p の範囲に色を塗る
ax.axvspan(0, p, color='yellow', alpha=0.3, label="0<a<pの範囲")
ax.set_title(f'n={n}, p={p}')
ax.set_xlabel('$a$')
ax.set_ylabel('値 (対数スケール)')
ax.set_yscale('log') # 縦軸を対数スケールに設定
ax.legend()
ax.grid(True, which="both", ls="--") # 対数スケールのグリッド
# サブプロット間のレイアウト調整
plt.tight_layout()
plt.show()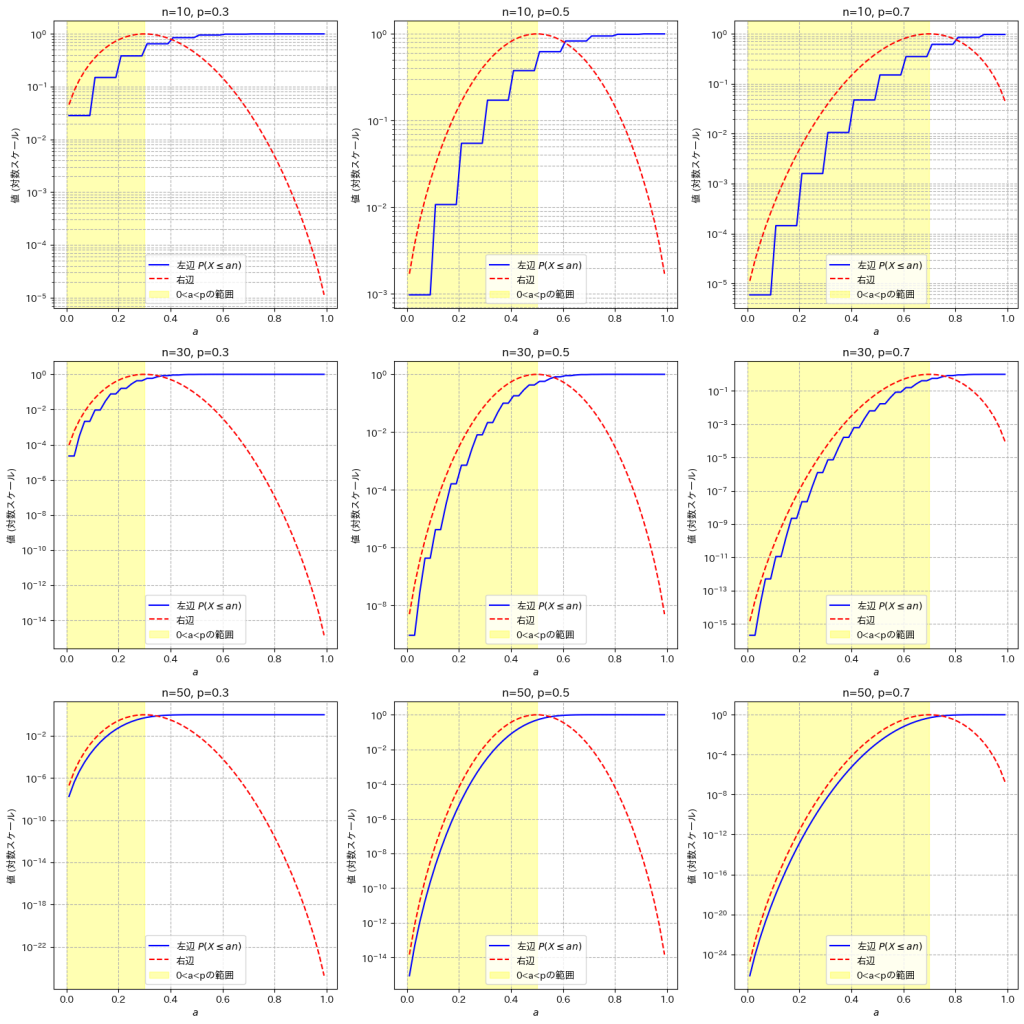
不等式は0<a<pの範囲で成り立っていることが確認できました。
確率母関数の微分と二階微分
二項分布の確率母関数 、その1階微分
、その1階微分  、および2階微分
、および2階微分  を視覚的に比較してみます。
を視覚的に比較してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy.misc import derivative
# パラメータ設定
n = 10 # 試行回数
p = 0.5 # 成功確率
# 確率母関数 G_X(t)
def G_X(t, n, p):
return (p * t + (1 - p))**n
# 1階微分 G'_X(t)
def G_X_diff_1(t, n, p):
return derivative(lambda t: G_X(t, n, p), t, dx=1e-6)
# 2階微分 G''_X(t)
def G_X_diff_2(t, n, p):
return derivative(lambda t: G_X_diff_1(t, n, p), t, dx=1e-6)
# t の範囲を定義
t_values = np.linspace(0, 1, 100)
# G_X(t), G'_X(t), G''_X(t) の値を計算
G_X_values = [G_X(t, n, p) for t in t_values]
G_X_diff_1_values = [G_X_diff_1(t, n, p) for t in t_values]
G_X_diff_2_values = [G_X_diff_2(t, n, p) for t in t_values]
# グラフの描画
plt.plot(t_values, G_X_values, label="G_X(t) (確率母関数)", color="blue")
plt.plot(t_values, G_X_diff_1_values, label="G'_X(t) (1階微分)", color="green")
plt.plot(t_values, G_X_diff_2_values, label="G''_X(t) (2階微分)", color="red")
plt.title(f"G_X(t), G'_X(t), G''_X(t) の比較 (n={n}, p={p})")
plt.xlabel("t")
plt.ylabel("値")
plt.legend()
plt.grid(True)
plt.show()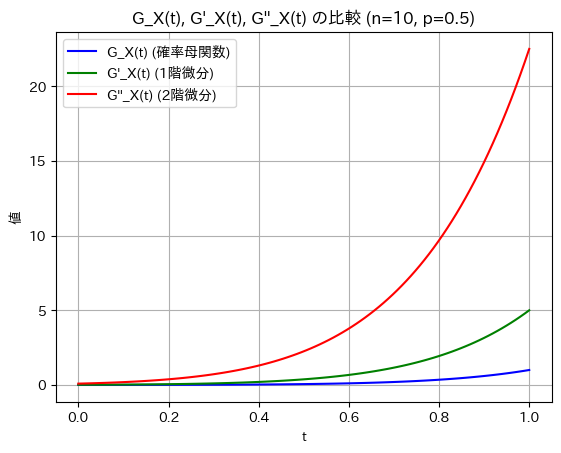
微分を重ねるごとにt=1付近での傾きが急になり大きな値を取っています。期待値や分散などの高次統計量に関連しているため、その値が大きくなっています。
豆の非復元抽出
豆の非復元抽出は超幾何分布になる
豆の実験の概要
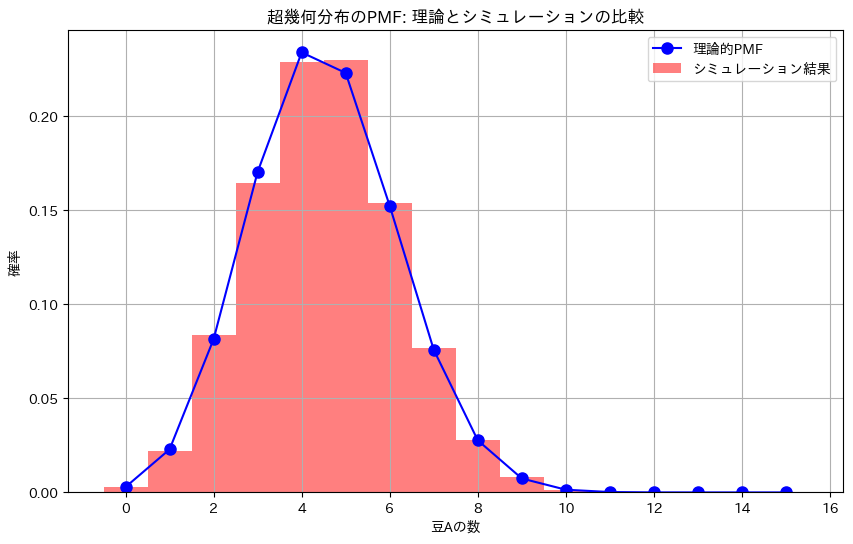
この実験は、100個の豆が入った袋の中から無作為に15個の豆を取り出し、その中に含まれる特定の種類の豆(豆A)の数を調べるシミュレーションを通じて、超幾何分布がどのように現実の状況を表現するかを確認するものです。
実験の設定:
- 袋の中の豆の総数: 100個
- 豆Aの数: 30個
- 豆Bの数: 70個
- 取り出す豆の数: 15個
実験の手順:
- 袋に入っている100個の豆のうち、30個が豆Aであり、残り70個が豆Bであるとします。
- 袋から無作為に15個の豆を非復元で抽出し、その中に含まれる豆Aの数を数えます。
- この抽出操作を10000回繰り返し、各回で得られた豆Aの数を記録します。
- 記録されたデータを基に、豆Aの数の分布をヒストグラムとして描画し、理論的に計算された超幾何分布と比較します。
実験の目的:
- この実験の目的は、理論的な超幾何分布が、豆を無作為に非復元抽出した際の豆Aの数の分布をどの程度正確に表現できるかを確認することです。
- 結果として得られるシミュレーションの分布が、理論的な超幾何分布とよく一致することが期待されます。これにより、超幾何分布が現実の非復元抽出を扱う際に有効であることが示されます。
結果の分析:
- シミュレーションの結果と理論的な超幾何分布を比較することで、両者の一致度を確認します。
- この実験は、非復元抽出のシナリオで生じる確率分布が、理論的な超幾何分布に従うことを実証的に示すものです。
シミュレーションによる計算
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import hypergeom
# パラメータの設定
M = 100 # 全体の豆の数
N_A = 30 # 豆Aの数
n = 15 # 抽出する豆の数
x_values = np.arange(0, n+1) # 可能な豆Aの数
# 理論的な超幾何分布のPMFを計算
rv = hypergeom(M, N_A, n)
pmf_theoretical = rv.pmf(x_values)
# 数値シミュレーションの設定
n_simulations = 10000 # シミュレーション回数
simulated_counts = []
# シミュレーションの実行
for _ in range(n_simulations):
# 袋の中の豆を表すリスト(1が豆A、0が豆B)
bag = np.array([1]*N_A + [0]*(M - N_A))
# 無作為に15個抽出
sample = np.random.choice(bag, size=n, replace=False)
# 抽出した中の豆Aの数をカウント
count_A = np.sum(sample)
simulated_counts.append(count_A)
# シミュレーションから得られたPMFを計算
pmf_simulated, bins = np.histogram(simulated_counts, bins=np.arange(-0.5, n+1.5, 1), density=True)
# グラフの描画
plt.figure(figsize=(10, 6))
# 理論的なPMFの描画
plt.plot(x_values, pmf_theoretical, 'bo-', label='理論的PMF', markersize=8)
# シミュレーション結果をヒストグラムとして描画
plt.hist(simulated_counts, bins=np.arange(-0.5, n+1.5, 1), density=True, alpha=0.5, color='red', label='シミュレーション結果')
# グラフの設定
plt.xlabel('豆Aの数')
plt.ylabel('確率')
plt.title('超幾何分布のPMF: 理論とシミュレーションの比較')
plt.legend()
plt.grid(True)
plt.show()