独立な指数分布に従う2変数の和の確率
指数分布の和はガンマ分布に従います。
X1,X2は互いに独立でパラメータλを持つ指数分布に従います。
U=X1+X2とします
数式を使ってUの確率密度関数を求めます。
import sympy as sp
# 変数の定義
x, u, lambda_value = sp.symbols('x u lambda', positive=True, real=True)
# 指数分布の確率密度関数 (PDF) f(x)
f_x = lambda_value * sp.exp(-lambda_value * x)
# 畳み込み積分を計算して、g(u) = f(x) * f(u - x) の形式にする
g_u = sp.integrate(f_x * lambda_value * sp.exp(-lambda_value * (u - x)), (x, 0, u))
# 簡略化
g_u_simplified = sp.simplify(g_u)
# 結果の表示
display(g_u_simplified)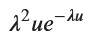
求まりました。
X1 (X2)と、Uの確率密度関数を重ねて描画してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2 の範囲
# X1, X2 の指数分布の確率密度関数 (PDF) - 同じなので1つにまとめる
pdf_X1_X2 = lambda_value * np.exp(-lambda_value * x_range)
# U = X1 + X2 は形状パラメータk=2、スケールパラメータθ=1/λのガンマ分布
u_range = np.linspace(0, 10, 1000)
pdf_U = gamma.pdf(u_range, a=2, scale=1/lambda_value)
# グラフのプロット
plt.figure(figsize=(8, 6))
# X1 (X2) の指数分布の描画
plt.plot(x_range, pdf_X1_X2, label='X1 (X2) (指数分布)', color='blue', linestyle='--')
# U のガンマ分布の描画
plt.plot(u_range, pdf_U, label='U = X1 + X2 (ガンマ分布)', color='red')
# グラフの装飾
plt.title('X1 (X2) と U の確率密度関数の比較')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.show()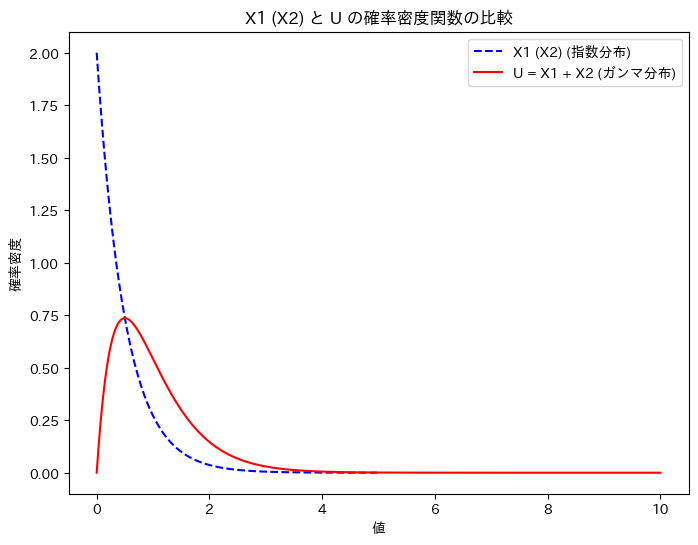
グラフの形状から、U = X1 + X2の関係は想像しづらいですね。
ガンマ分布の形状パラメータを1~2に変化させて、X1 (X2)からUへの変化を確認します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2, U の範囲を0~5に設定
# ガンマ分布の形状パラメータを1から2まで0.1ずつ変化させる
shape_params = np.arange(1, 2.1, 0.1) # 1から2までの形状パラメータを0.1ステップで変化
# グラフのプロット
plt.figure(figsize=(8, 6))
# 形状パラメータが1から2に変化するガンマ分布の描画
for k in shape_params:
gamma_pdf = gamma.pdf(x_range, a=k, scale=1/lambda_value)
plt.plot(x_range, gamma_pdf, label=f'形状パラメータ k={k:.1f}')
# X1 (X2) の指数分布の描画 - 同じなので1つにまとめる
pdf_X1_X2 = lambda_value * np.exp(-lambda_value * x_range)
plt.plot(x_range, pdf_X1_X2, label='X1 (X2) (指数分布)', color='blue', linestyle='--')
# グラフの装飾
plt.title('指数分布からガンマ分布への変化 (形状パラメータの0.1ステップ変化)')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.show()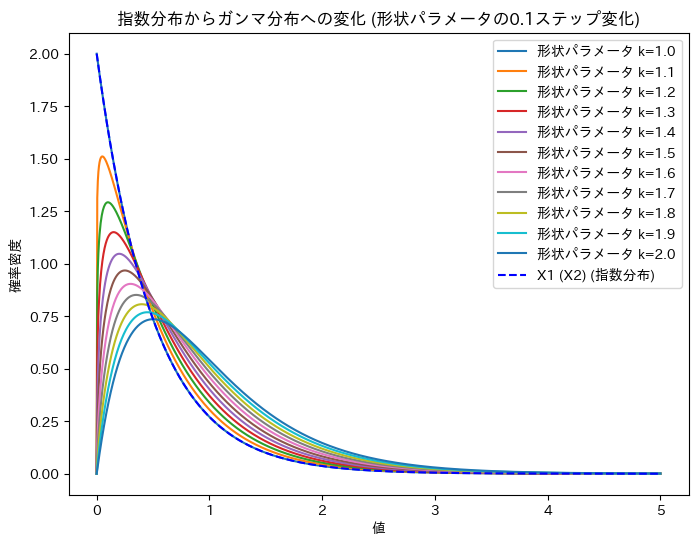
X1 (X2)からUへの変化が可視化できました。
次に、X1 (X2)と、Uの累積分布関数を重ねて描画してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import expon, gamma
# パラメータ設定
lambda_value = 2 # λ=2
x_range = np.linspace(0, 5, 1000) # X1, X2 の範囲
# X1, X2 の指数分布の累積分布関数 (CDF) - 同じなので1つにまとめる
cdf_X1_X2 = expon.cdf(x_range, scale=1/lambda_value)
# U = X1 + X2 は形状パラメータk=2、スケールパラメータθ=1/λのガンマ分布
u_range = np.linspace(0, 10, 1000)
cdf_U = gamma.cdf(u_range, a=2, scale=1/lambda_value)
# グラフのプロット
plt.figure(figsize=(8, 6))
# X1 (X2) の指数分布のCDFの描画
plt.plot(x_range, cdf_X1_X2, label='X1 (X2) (指数分布 CDF)', color='blue', linestyle='--')
# U のガンマ分布のCDFの描画
plt.plot(u_range, cdf_U, label='U = X1 + X2 (ガンマ分布 CDF)', color='red')
# グラフの装飾
plt.title('X1 (X2) と U の累積分布関数 (CDF) の比較')
plt.xlabel('値')
plt.ylabel('累積確率')
plt.legend()
# グラフの表示
plt.show()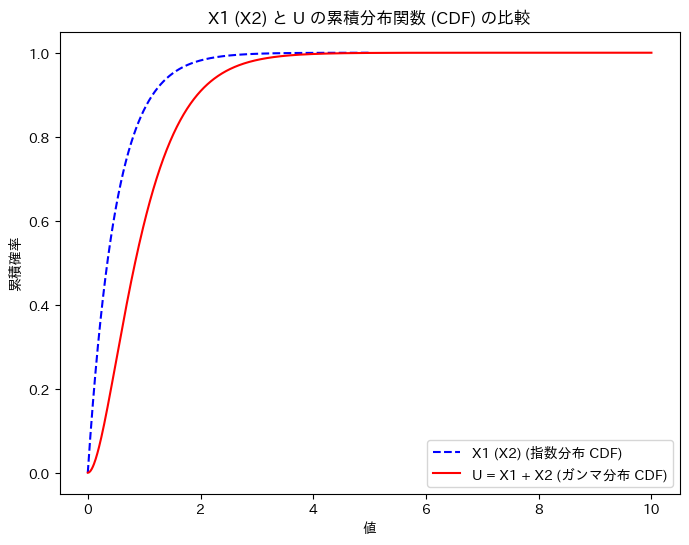
グラフの形状から、U = X1 + X2の関係を想像しやすくなりました。
負の二項分布
ポアソン-ガンマ混合分布は、負の二項分布になる
数式を使った計算
import sympy as sp
# 定義
k = sp.symbols('k', integer=True)
alpha, beta = sp.symbols('alpha beta', positive=True)
lambda_var = sp.symbols('lambda', positive=True)
# ポアソン分布の確率質量関数
poisson_pmf = (lambda_var**k * sp.exp(-lambda_var)) / sp.factorial(k)
# ガンマ分布の確率密度関数
gamma_pdf = (beta**alpha / sp.gamma(alpha)) * lambda_var**(alpha - 1) * sp.exp(-beta * lambda_var)
# 周辺分布の計算
marginal_distribution = sp.integrate(poisson_pmf * gamma_pdf, (lambda_var, 0, sp.oo)).simplify()
marginal_distribution
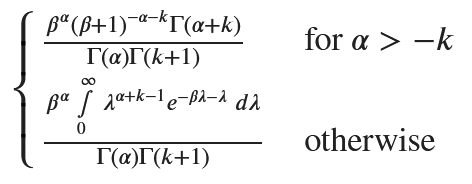
次式と同じなので、負の二項分布となる。

シミュレーションによる計算
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma, nbinom
# パラメータの設定
alpha = 3.0
beta = 2.0
sample_size = 10000
# ガンマ分布から λ を生成
lambda_samples = np.random.gamma(alpha, 1/beta, sample_size)
# 生成された λ を使ってポアソン分布から X を生成
poisson_samples = [np.random.poisson(lam) for lam in lambda_samples]
# 負の二項分布のパラメータを設定
r = alpha
p = beta / (beta + 1)
# 負の二項分布から理論的な確率質量関数を計算
x = np.arange(0, max(poisson_samples) + 1)
nbinom_pmf = nbinom.pmf(x, r, p)
# ヒストグラムの描画
plt.hist(poisson_samples, bins=np.arange(0, max(poisson_samples) + 1) - 0.5, density=True, alpha=0.75, color='blue', edgecolor='black', rwidth=0.8)
# 理論的な負の二項分布の確率質量関数をプロット
plt.plot(x, nbinom_pmf, 'r', linestyle='-', label='理論的な負の二項分布')
# グラフのタイトルとラベル
plt.title('ポアソン-ガンマ混合分布のシミュレーション結果')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.grid(True)
plt.show()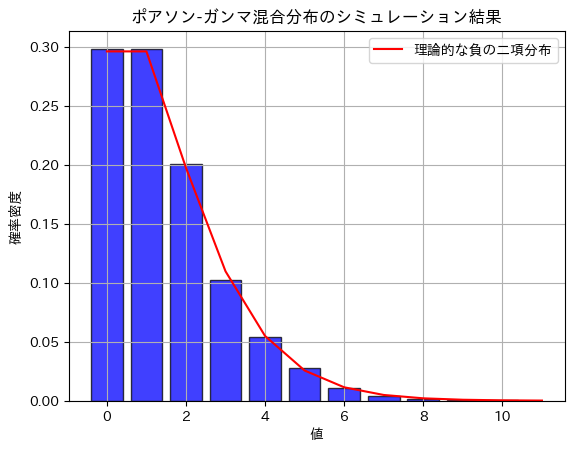
ガンマ分布
ガンマ分布の期待値と分散の導出
数式を使った計算
import sympy as sp
# 定義
lambda_var = sp.symbols('lambda')
alpha, beta = sp.symbols('alpha beta', positive=True)
# ガンマ分布の確率密度関数
gamma_pdf = (beta**alpha / sp.gamma(alpha)) * lambda_var**(alpha-1) * sp.exp(-beta * lambda_var)
# 期待値 E[Λ] の計算
expected_value = sp.integrate(lambda_var * gamma_pdf, (lambda_var, 0, sp.oo)).simplify()
# E[Λ^2] の計算
expected_value_Lambda2 = sp.integrate(lambda_var**2 * gamma_pdf, (lambda_var, 0, sp.oo)).simplify()
# 分散 V[Λ] の計算
variance = (expected_value_Lambda2 - expected_value**2).simplify()
# 結果を辞書形式で表示
{
"期待値 E[Λ]": expected_value,
"分散 V[Λ]": variance
}{'期待値 E[Λ]': alpha/beta, '分散 V[Λ]': alpha/beta**2}シミュレーションによる計算
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
# パラメータ α と β の設定
alpha = 3.0
beta = 2.0
# サンプルサイズ
sample_size = 10000
# ガンマ分布に従う乱数を生成
samples = np.random.gamma(alpha, 1/beta, sample_size)
# 期待値と分散の計算
expected_value = np.mean(samples)
variance = np.var(samples)
# 結果の表示
print(f"期待値のシミュレーション結果: {expected_value}")
print(f"分散のシミュレーション結果: {variance}")
# ヒストグラムの描画
plt.hist(samples, bins=50, density=True, alpha=0.75, color='blue', edgecolor='black')
# 理論的なガンマ分布の確率密度関数をプロット
x = np.linspace(0, max(samples), 100)
gamma_pdf = gamma.pdf(x, alpha, scale=1/beta)
plt.plot(x, gamma_pdf, 'r', linestyle='-', label='理論的なガンマ分布')
# グラフのタイトルとラベル
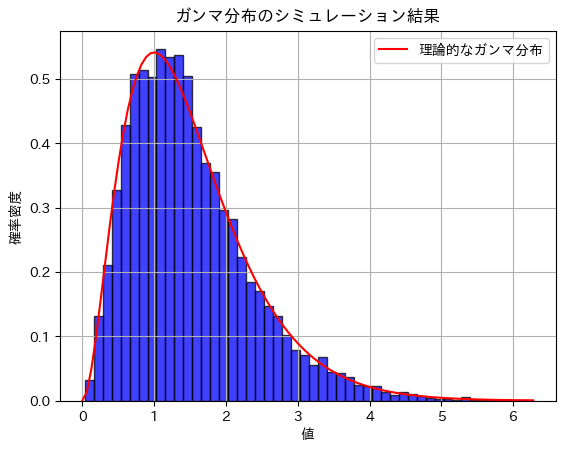
plt.title('ガンマ分布のシミュレーション結果')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.grid(True)
plt.show()期待値のシミュレーション結果: 1.4947527551017439
分散のシミュレーション結果: 0.7452822182213243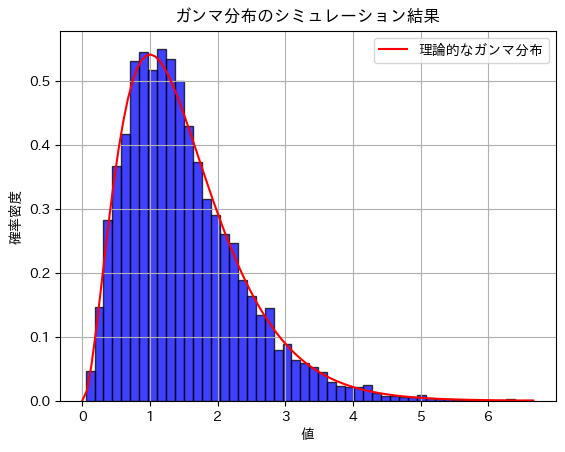
シミュレーションによる計算 (ガンマ分布に従う乱数生成関数をスクラッチで記述)
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
def custom_exponential(beta):
# [0, 1) の一様乱数を生成
u = np.random.rand()
# 指数分布に従う乱数を生成
return -np.log(u) / beta
def custom_gamma(alpha, beta, sample_size):
samples = []
for _ in range(sample_size):
sample = sum(custom_exponential(beta) for _ in range(int(alpha)))
samples.append(sample)
return samples
# パラメータ α と β の設定
alpha = 3.0
beta = 2.0
# サンプルサイズ
sample_size = 10000
# カスタム関数を使ってガンマ分布に従う乱数を生成
samples = custom_gamma(alpha, beta, sample_size)
# 期待値と分散の計算
expected_value = np.mean(samples)
variance = np.var(samples)
# 理論値
theoretical_expected_value = alpha / beta
theoretical_variance = alpha / beta**2
# 結果の表示
print(f"シミュレーション結果 - 期待値: {expected_value}, 理論値: {theoretical_expected_value}")
print(f"シミュレーション結果 - 分散: {variance}, 理論値: {theoretical_variance}")
# ヒストグラムの描画
plt.hist(samples, bins=50, density=True, alpha=0.75, color='blue', edgecolor='black')
# 理論的なガンマ分布の確率密度関数をプロット
x = np.linspace(0, max(samples), 100)
gamma_pdf = gamma.pdf(x, alpha, scale=1/beta)
plt.plot(x, gamma_pdf, 'r', linestyle='-', label='理論的なガンマ分布')
# グラフのタイトルとラベル
plt.title('ガンマ分布のシミュレーション結果')
plt.xlabel('値')
plt.ylabel('確率密度')
plt.legend()
# グラフの表示
plt.grid(True)
plt.show()
シミュレーション結果 - 期待値: 1.4966126702823181, 理論値: 1.5
シミュレーション結果 - 分散: 0.7242038142114708, 理論値: 0.75